 TEL:+86 158 1857 3751
TEL:+86 158 1857 3751 




















































1. The Evolution Toward Ultra-Scale AI Computing

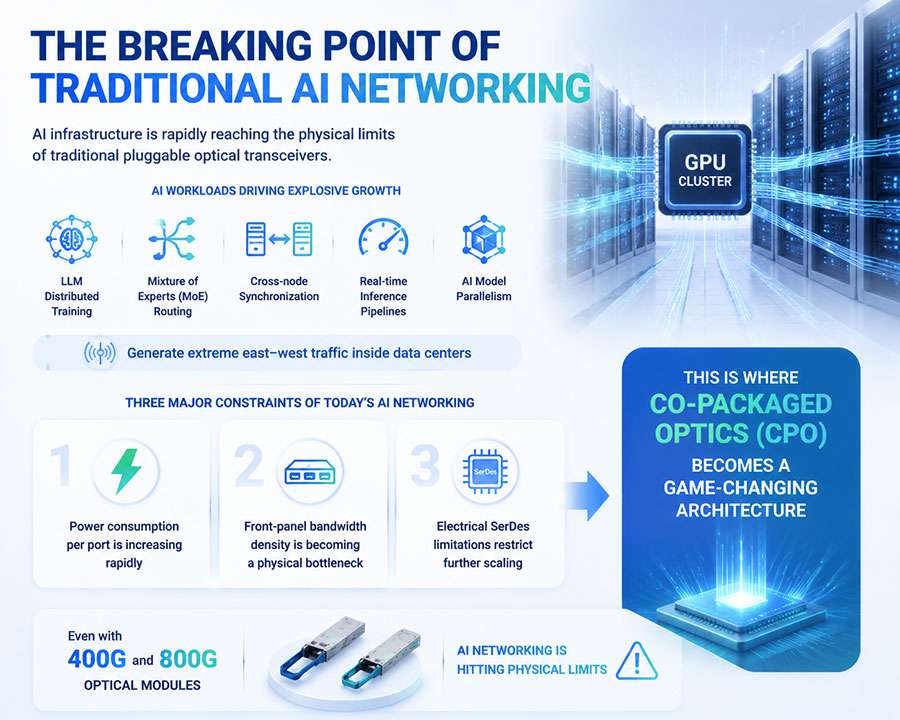
Artificial Intelligence is entering a new phase of exponential growth. The transition from traditional cloud computing to GPU-dominated AI clusters has fundamentally changed data center networking requirements.
Modern AI workloads such as:
Large Language Model (LLM) training
Mixture of Experts (MoE) architectures
Distributed inference pipelines
Multi-node parameter synchronization
Real-time AI reasoning systems
require massive east-west traffic exchange between GPUs and compute nodes.
As model sizes move from billions to trillions of parameters, the network becomes the primary bottleneck—not compute.
This is where 1.6T networking emerges as the next critical milestone beyond 400G and 800G.
2. Why 800G Is Not Enough for Future AI Clusters

800G networking is currently being deployed in next-generation AI systems powered by advanced GPUs such as NVIDIA Blackwell.
However, AI scaling trends show three structural challenges:
GPU density per rack continues to increase
Model parallelism requires more frequent synchronization
Network oversubscription must be minimized
Even with 800G links, hyperscale AI clusters still face:
Congestion in spine layers
Increased hop latency
Higher port consumption per switch
Rising energy cost per bit
As a result, AI infrastructure designers are already planning the transition toward 1.6T interconnects.
3. What Makes 1.6T Networking Different?
1.6T (1.6 Terabits per second) represents the next-generation optical interconnect standard designed for ultra-large AI fabrics.
Key Advantages
2× bandwidth of 800G
Reduced switch port count per cluster
Lower network hop complexity
Improved energy efficiency per bit
Better scalability for trillion-parameter models
Architectural Impact
With 1.6T links, AI data centers can:
Reduce fabric oversubscription
Flatten network topology
Improve GPU utilization
Support larger distributed training jobs
In practice, 1.6T enables AI clusters with significantly fewer network bottlenecks and higher training efficiency.
4. Where 1.6T Will Be Used in AI Data Centers
4.1 GPU-to-GPU and Rack-Level Fabric
In ultra-large GPU clusters, 1.6T will primarily be used for:
GPU server uplinks
High-density ToR switching
Intra-cluster aggregation layers
C-LIGHT is developing next-generation high-speed interconnect solutions, including:
1.6T OSFP-XD DAC (short reach, ultra-low latency)
1.6T AOC solutions for high-density GPU racks
Early-stage 1.6T optical module ecosystems
4.2 Leaf-Spine Backbone Networks
At the aggregation and spine layers:
1.6T reduces the number of required switch ports
Improves bisection bandwidth
Simplifies large-scale AI fabric design
C-LIGHT supports AI backbone evolution with:
800G OSFP 2DR4 and 800G OSFP 2FR4 modules
Transition-ready 1.6T optical architectures
DWDM-based scalable backbone solutions
4.3 Data Center Interconnect (DCI)
For multi-building AI campuses:
1.6T enables higher capacity per fiber pair
Reduces long-haul link cost per bit
Supports hyperscale AI cloud expansion
C-LIGHT DWDM and coherent-ready solutions provide a foundation for:
400G / 800G / future 1.6T DWDM systems
MUX/DEMUX optical transport platforms
Long-distance AI cluster connectivity
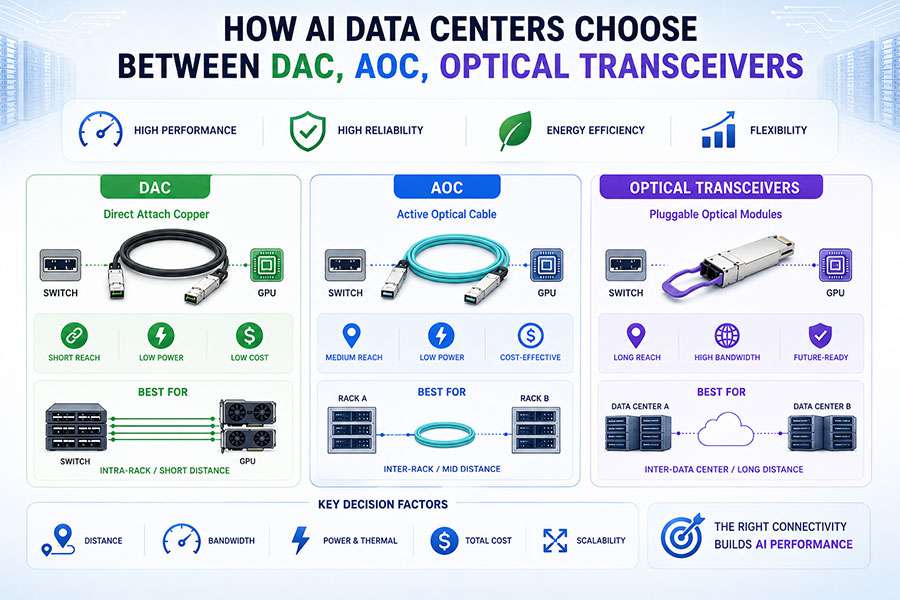
5. Transition Path: From 400G to 1.6T
AI networking evolution follows a clear progression:
400G → Mainstream AI infrastructure
800G → High-density AI clusters
1.6T → Ultra-scale AI supercomputing fabric
Typical Migration Strategy:
Existing clusters: 400G DR4 / FR4 backbone
New deployments: 800G OSFP / 800G QSFP-DD
Future systems: 1.6T OSFP-XD ecosystem
C-LIGHT provides full lifecycle support:
400G DAC / AOC / optical modules
800G high-density AI interconnects
Research and deployment roadmap toward 1.6T solutions
6. Technical Drivers Behind 1.6T Adoption
6.1 GPU Compute Scaling
Next-generation AI models require:
Larger parameter sets
More distributed training nodes
Faster synchronization cycles
Network bandwidth must scale proportionally.
6.2 Ethernet and InfiniBand Evolution
Industry roadmaps indicate:
800G becoming mainstream baseline
1.6T emerging as next IEEE/industry milestone
Continuous improvement in PAM4 and SerDes technologies
6.3 Energy Efficiency Pressure
AI data centers face extreme power density challenges:
40kW–100kW+ per rack
Rising cooling demands
Increasing cost per watt
1.6T reduces:
Number of transceivers per cluster
Total power consumption per bit
Cooling overhead per rack
7. C-LIGHT’s Role in Next-Generation AI Networking
C-LIGHT provides a full-stack high-speed interconnect portfolio designed for AI evolution:
7.1 400G Solutions
AI storage and training network connectivity
7.2 800G Solutions
800G OSFP / 800G QSFP-DD DAC
800G 2DR4 / 2FR4 optical modules
High-density AI fabric optimization
7.3 Future 1.6T Readiness
OSFP-XD ecosystem planning
Ultra-high-speed DAC/AOC architecture research
DWDM scalability for AI interconnect evolution
7.4 Supporting Infrastructure
CWDM/DWDM MUX/DEMUX systems
Compatibility testing for NVIDIA / Broadcom / Intel platforms
BER, eye diagram, and reliability validation services
These capabilities ensure that AI operators can smoothly transition from 400G → 800G → 1.6T without redesigning their entire infrastructure.
8. Conclusion
1.6T networking is not just an incremental upgrade—it is a structural shift in AI data center architecture.
As AI models scale toward trillion-parameter systems, only ultra-high-speed interconnects can support the required:
Bandwidth density
Low latency synchronization
Efficient GPU utilization
Large-scale distributed computing
While 400G and 800G remain the foundation of today’s AI infrastructure, 1.6T defines the future of hyperscale AI computing.
With a complete roadmap spanning 400G, 800G, and next-generation 1.6T interconnect technologies, C-LIGHT enables AI data centers to build scalable, efficient, and future-ready networking architectures for the next decade of artificial intelligence.








 >
>

 >
>
 >
>
 >
>
 >
>
 >
>
 >
>
 >
>
 >
>
 >
>




